Cloudflare представила новый инструмент, который позволит владельцам веб-сайтов контролировать и монетизировать доступ искусственного интеллекта к своему контенту.
Как отмечается в пресс-релизе компании, данный шаг является ответом на растущее число ИИ-краулеров , которые загружают контент без согласия его автора и зачастую без компенсации, «разрушая традиционную модель монетизации контента, основанную на трафике со страниц поисковых систем«.
Не пропустите: С ИИ Google может остаться без авторов и… без поиска?
Новая система, основанная на модели «pay per crawl» (оплата за сканирование) позволяет владельцам контента устанавливать как возможность, так и цену доступа ИИ к данным.
Таким образом, в рамках этой системы Cloudflare предлагает авторам способ получать прямую финансовую компенсацию за использование их контента для обучения моделей ИИ.
Инициативу уже поддержали такие крупные медиа, как Condé Nast и Associated Press, а также технологические платформы Reddit и Pinterest .
По словам Стефани Коэн, директора по стратегии Cloudflare, инструмент в первую очередь призван вернуть контроль над контентом тем, кто его создает , и способствовать появлению устойчивой интернет-экосистемы, в которой авторы занимают справедливую позицию по отношению к компаниям, разрабатывающим ИИ.
В Cloudflare нынешний подход крупных разработчиков ИИ к чужому контенту называют «часто однобоким».
Ссылаясь на собственные данные, в компании отмечают, что,
«…к примеру, Google теперь ссылается на исходную страницу в соотношении 18:1 для каждого сканирования контента, а OpenAI в «экстремальном» соотношения 1500:1 , что иллюстрирует, насколько значительно поток трафика сместился в пользу больших языковых моделей».
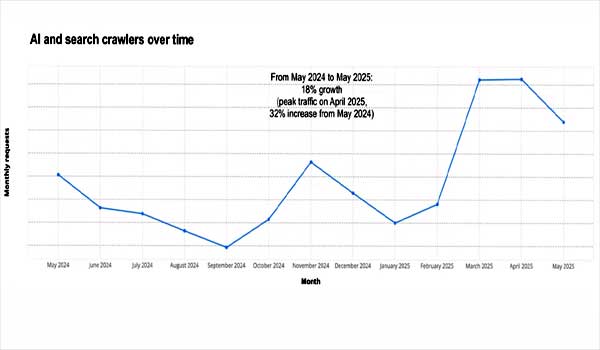
В пресс-релизе также упоминается, что New York Times и ряд других крупных СМИ пошли по пути судебных разбирательств и уже подали иски о нарушении авторских прав против компаний-разработчиков ИИ.
Другие компании предпочитают заключать коммерческие соглашения о лицензировании контента , как, например, Reddit, который одновременно подал в суд на Anthropic за несанкционированное использование комментариев пользователей, но также заключил лицензионное соглашение с Google.
Новое решение от Cloudflare, как подчеркивают в компании, «прокладывает путь к следующей модели Интернета, в которой свободный и неконтролируемый сбор данных перестанет быть обычным явлением, а издатели будут играть активную роль в определении стоимости своих цифровых активов«.